 输入URL背后的技术步骤
输入URL背后的技术步骤
# # 输入URL背后的技术步骤
一道经典的面试题,涵盖的知识点非常多,这里解答下该问题,以对自己的知识体系进行梳理。
- 系统层
- 发起http请求,解析域名
- DNS
- Chrome搜索自身DNS缓存。chrome输入
chrome://net-internals/#dns可查看到 - 搜索操作系统自身DNS缓存
- 读取本地HOST文件
- 以上都查询不到时,浏览器发送一个DNS的系统调用,DNS请求到达宽带运营商服务器。
- 宽带运营商服务器查询自身缓存
- 没查询时,发起一个迭代(顶级域--次级域名--...)的DNS解析请求,直到获取到域名对应的IP地址。
- 拿到域名对应的IP并缓存
- 宽带运营商服务器缓存DNS
- 结果返回操作系统并缓存DNS
- 结果返回浏览器并缓存DNS
- 得到目标IP,发起Http“三次握手”,建立起TCP/IP连接
- 客户端发送一个带有SYN标志的数据包给服务端
- 服务端回传一个带有SYN/ACK标志的数据包
- 客户端再回传一个带ACK标志的数据包给服务端
- 连接成功后,浏览器向服务器发起标准Http请求
- 构建Http请求报文
- 请求行。 * 格式:Method Request-URL HTTP-Version CRLF,如:GET index.html HTTP/1.1 * Method可选项:GET, POST, PUT, DELETE, OPTIONS, HEAD
- 请求报头 * 允许客户端向服务器传递请求的附加信息 * 常见请求报头:Content-Type, Cache-Control,CookieAccept-Encoding,Accept-Language,等
- 请求正文 * 当使用POST, PUT等方法时,通常需要客户端向服务器传递数据。
- 通过TCP协议,发送到服务器指定端口(Http协议默认80端口、Https协议默认443)
- 服务器收到请求后,经过后端处理返回结果。(前后端分离)
- 响应报文 * 状态码 * 1xx:指示信息–表示请求已接收,继续处理。 * 2xx:成功–表示请求已被成功接收、理解、接受。 * 3xx:重定向–要完成请求必须进行更进一步的操作。 * 4xx:客户端错误–请求有语法错误或请求无法实现。 * 5xx:服务器端错误–服务器未能实现合法的请求。 * 响应报头 * 响应报文
- 返回Html页面等资源,html包含css/js等资源,重复以上http请求
- 渲染层
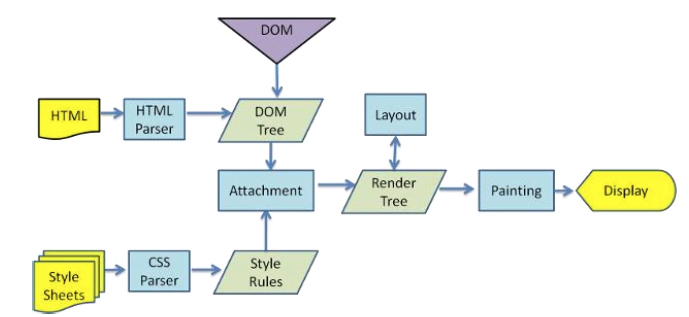
- Chrome浏览器的渲染引擎 Blink(常说的浏览器内核)边接收边解析 HTML 内容,浏览器自上而下逐行解析 HTML 内容,经过词法分析、语法分析,
构建 DOM 树。HTML文档被加载和解析完成时(DOM树构建完成),触发DOMContentLoaded事件,此时页面可以渲染展示出内容了。(html引用的图片可能还在http请求加载,当所有资源全部请求完成,触发load事件)
- 当遇到外部 CSS 链接时,不阻塞而继续构建 DOM 树。
- 当遇到外部 JS 链接时,异步获取资源。JS下载后,V8引擎(常说的JavaScript引擎)会解析、编译JS内容。由于 JS 可能会修改 DOM 树和 CSSOM 树而造成回流和重绘,故JS会阻塞DOM树的构建。
- 下载CSS后,主线程会在合适时机解析CSS内容,
构建 CSSOM 树。本来构建DOM树和CSSOM树是并行的,互不影响,但当解析到上文提到的JavaScript时,需要构建完成CSSOM树后,才能执行js代码(DOM树此时被挂起),因为js可以查询/修改任意对象的样式,此时需要CSSOM树构建完成。 - 浏览器结合 DOM 树和 CSSOM 树
构建 Render 树。Render树与DOM树不同,渲染树中并没有head、display为none等不必显示的节点。 - 浏览器渲染(布局 + 绘制 + 复合图层化),布局(Layout)环节主要负责各元素尺寸、位置的计算,绘制(Paint)环节则是绘制页面像素信息,合成(Composite)环节是多个复合层的合成,最终合成的页面被用户看到。
- 回流:DOM节点中的各个元素都是以盒模型的形式存在,这些都需要浏览器去计算其位置和大小等
- 重绘:当盒模型的位置,大小以及其他属性,如颜色,字体,等确定下来之后,浏览器便开始绘制内容
- Chrome浏览器的渲染引擎 Blink(常说的浏览器内核)边接收边解析 HTML 内容,浏览器自上而下逐行解析 HTML 内容,经过词法分析、语法分析,
html内容从上到下解析,浏览器遇到body标签开始显示内容。CSS 不会阻塞 DOM 的解析,JS 会阻止DOM的解析。
当文档加载过程中遇到JS文件,HTML文档会挂起渲染过程,不仅要等到文档中JS文件加载完毕还要等待解析执行完毕,才会继续HTML的渲染过程。
现代浏览器都使用了预加载器,在js挂起DOM解析时,会继续解析后面的html,寻找需要下载的资源。预加载器下载这些资源,以减少JS阻塞带来的影响。
# # 优化
了解以上,我们就能知道以下这些前端优化点:
- http请求数减少,如:雪碧图、合并CSS/JS文件、缓存资源等(针对http1.1)
- http请求资源体积减少,如:启用gzip压缩、图片压缩、减少cookie、按需加载等
- css放在head中。由于同时具有 DOM 和 CSSOM 才能构建渲染树,所以HTML 和 CSS 都是阻塞渲染的资源,所以尽量精简CSS也是优化方式之一。
- js放在body底部,减少白屏时间。因为js会阻止浏览器解析。
- 减少回流和重绘制,比如不要一条一条修改DOM样式、使用documentFragment操作DOM等。
# # 衍生问题
- 响应报文304作用以及缓存相关
- js事件循环(event loop)
# # 参考文章
编辑 (opens new window)