 Markdown-It 解析原理
Markdown-It 解析原理
# # Markdown-It 解析原理
markdown-it是目前使用最广泛的markdown解析器工具。它将markdown语法的文件,解析为最终的html文件。绝大部分文档中心框架工具如Vuepress,处理markdown文件部分都是使用该工具以及扩展出的插件。了解它的解析过程,是进行自定义markdown插件的前提。
解析主要分两步:
- Parser:将md文档解析为Tokens(类似ATS)
- Renderer:将Tokens内容渲染为html
var md = require('markdown-it')();
// render函数包含了parser和renderer阶段
var result = md.render('# markdown-it rulezz!');
2
3
4
# # Parser
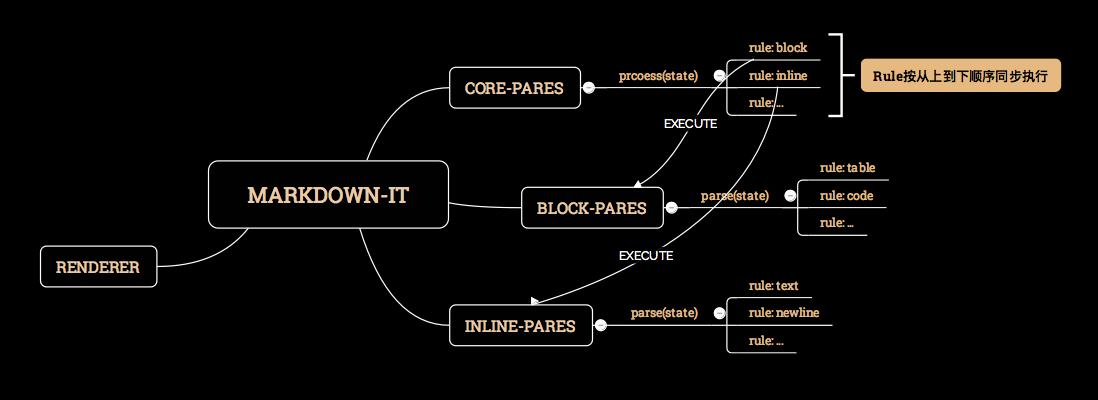
创建一个 Core Parser,这个 Core Parser 包含一系列的缺省 Rules。这些 Rules 将顺序执行,每个 Rule 都在前面的 Tokens 的基础上,要么修改原来的 Token,要么添加新的 Token。这个 Rules 的链条被称为Core Chain。Core Rules 如下:
- normalize: MD 文档的换行符统一化;将空字符 \u0000 转换为 \uFFFD
- block: 识别出哪些是 Block Token(Table, blockquote, Code, Fence 等),哪些是 Inline Token。如果是 Block Token,则启动 Block Chain 来处理。
Block Chain又是一堆 Rules 的执行。 - inline: 针对 Block Rule 识别出来的 'inline' 类型的进行
Inline Chain处理。 - linkify: 检测 text 类型的 token 中是否有可是别的 URL(http 或者 mailto),如果有,则将原本完整的 text token 分为 text, link, text 三部分(实际不只三个 tokens, 因为 link_open, link_close 这些 tokens 都会被产生)
- replacements: 完成诸如 (c) (C) → © ,+- → ±的替换,同时躲开 link 中的包含的对象文字
- smartquotes: 完成引号的排印化处理
Rule Chain核心代码:
// 定义parse
var Ruler = require('./ruler');
var _rules = [
[ 'normalize', require('./rules_core/normalize') ],
[ 'block', require('./rules_core/block') ],
[ 'inline', require('./rules_core/inline') ],
[ 'linkify', require('./rules_core/linkify') ],
[ 'replacements', require('./rules_core/replacements') ],
[ 'smartquotes', require('./rules_core/smartquotes') ]
];
function Core() {
// Ruler类在Block Chain和Inline Chain都有应用
this.ruler = new Ruler();
for (var i = 0; i < _rules.length; i++) {
this.ruler.push(_rules[i][0], _rules[i][1]);
}
}
Core.prototype.process = function (state) {
var i, l, rules;
rules = this.ruler.getRules('');
for (i = 0, l = rules.length; i < l; i++) {
rules[i](state);
}
};
// State是数据结构
// 所以链式调用Rule,修改的内容是数据结构State
Core.prototype.State = require('./rules_core/state_core');
module.exports = Core;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
// 调用
var core = new Core()
let tokens = core.process(new core.State(...))
2
3
4
解析出Tokens数据结构类似如下:
[
{
"type": "heading_open",
"tag": "h1",
"attrs": null,
"map": [
0,
1
],
"nesting": 1,
"level": 0,
"children": null,
"content": "",
"markup": "#",
"info": "",
"meta": null,
"block": true,
"hidden": false
},
{
"type": "inline",
"tag": "",
"attrs": null,
"map": [
0,
1
],
"nesting": 0,
"level": 1,
"children": [
{
"type": "text",
"tag": "",
"attrs": null,
"map": null,
"nesting": 0,
"level": 0,
"children": null,
"content": "test",
"markup": "",
"info": "",
"meta": null,
"block": false,
"hidden": false
}
],
"content": "test",
"markup": "",
"info": "",
"meta": null,
"block": true,
"hidden": false
},
{
"type": "heading_close",
"tag": "h1",
"attrs": null,
"map": null,
"nesting": -1,
"level": 0,
"children": null,
"content": "",
"markup": "#",
"info": "",
"meta": null,
"block": true,
"hidden": false
}
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
# # Renderer
把特定 Token 转变为特定的 HTML 的过程。
遇到匹配的 token.type,那么就会用对应的 Renderer Rule 来渲染。没有找到对应的 Renderer Rule,那么一个缺省的 render 函数会被调用。
markdown-it提供了强大的扩展机制(Plugin)。markdown-it提供了一些常用token.type对应的render规则,当你需要某些特殊的渲染效果时,可以覆写这些render rule,比如VuePress (opens new window) (opens new window)。另外,由于是把markdown解析成中间token数据结构,你还可以自定义插件,实现自定义parse rule以及对应的render rule,来扩展markdown-it能力,比如markdown-it-emoji (opens new window) (opens new window)。